The Government of Ontario collects a huge amount of data on provincial programs and infrastructure, and much of it is provided as open data sets for public use. In this assignment, we’ll work with a particular dataset that contains information about provincially owned and maintained bridges in Ontario. All bridges in Ontario are reviewed every 2 years, and their information is collected to help determine when bridges need inspection and maintenance. The data you’ll be working with contains information about all bridges in the Ontario highway network, such as the length of the bridges, their condition over various years, and historical information.
We have included two datasets in your starter files: bridge_data_small.csv and bridge_data_large.csv (do not download the files from the Government of Ontario – use only the datasets in the starter files). These are Comma Separated Value (CSV) files, which contain the data in a table-format similar to a spreadsheet. Each row of the table contains information about a bridge. And each column of the table represents a “feature” of that bridge. For example, the latitude and longitude columns tell us the precise location of the bridge. If you would like to take a peek at the data, we recommend opening the files with a spreadsheet program (e.g., Excel) rather than using a Python IDE to open them.
Here is a screenshot of the data opened in Microsoft Excel (your computer may have a different spreadsheet program installed):
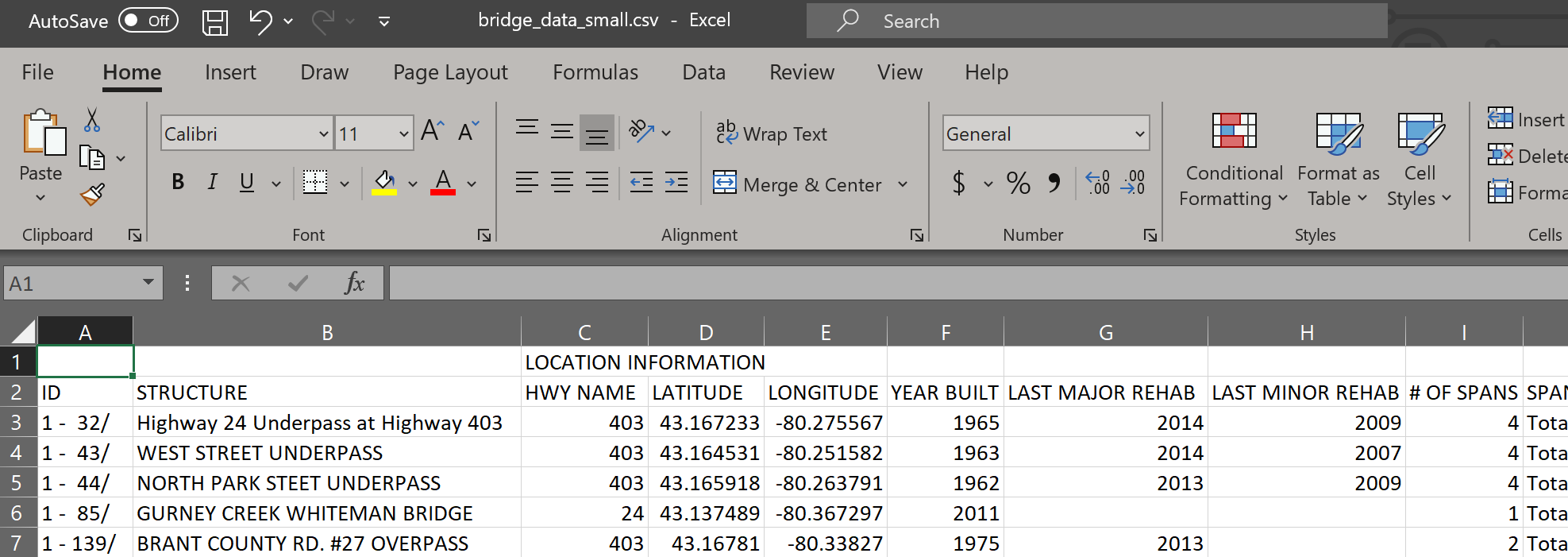
We can see that the first bridge is described on row 3. From row 3, column B, we can see that the bridge is named: Highway 24 Underpass at Highway 403. Subsequent columns include even more information about the bridge.
Ontario sends inspectors to check the condition of a bridge. The dataset contains a column (LAST INSPECTION DATE) showing the last date a bridge was inspected. When a bridge is inspected, it receives score based on its condition. This score is called the Bridge Condition Index (BCI). The BCI is a number between 0 and 100, inclusive. You can see the most recent score in the dataset (CURRENT BCI), as well as past scores (the columns with years ranging from 2013 to 2000).
If a bridge is in poor condition, it can be fixed (i.e., “rehabilitated”). These can be major or minor fixes. The dataset includes the year the last major (LAST MAJOR REHAB) or minor (LAST MINOR REHAB) rehabilitation was performed on the bridge.
A bridge is made up of one or more spans (# OF SPANS). A span “is the distance between two intermediate supports for a structure, e.g. a beam or a bridge. A span can be closed by a solid beam or by a rope” (Source: Wikipedia). Each span has a length associated with it (SPAN DETAILS). For example, if a bridge has two spans, the SPAN DETAILS data follows the following format:
Total=60.6 (1)=30.3;(2)=30.3;More generally, the format is:
Total=[total length of all spans] (1)=[the length of the first span];(2)=[the length of the second span]; and so on for each span of the bridge;Some things to notice about this format:
(x)= where x is a number starting from 1 and increasing by 1 for every span.We will represent the dataset as a list of lists in Python (i.e., List[list]). The outer list has the same length as the number of bridges in the dataset. Each inner list (i.e., list) corresponds to one row (i.e., bridge) of the dataset. For example, here is what the first bridge of our dataset will look like in our Python program:
>>> MISSING_BCI = -1.0
>>> first_bridge = [
... 1, 'Highway 24 Underpass at Highway 403',
... '403', 43.167233, -80.275567, '1965', '2014', '2009', 4,
... [12.0, 19.0, 21.0, 12.0], 65.0, '04/13/2012',
... [['2013', '2012', '2011', '2010', '2009', '2008', '2007',
... '2006', '2005', '2004', '2003', '2002', '2001', '2000'],
... [MISSING_BCI, 72.3, MISSING_BCI, 69.5, MISSING_BCI, 70.0, MISSING_BCI,
... 70.3, MISSING_BCI, 70.5, MISSING_BCI, 70.7, 72.9, MISSING_BCI]]
... ]The variable first_bridge has the general type list. Notice how the elements inside the list are not all the same type. The list includes:
1, 4)'403', '04/13/2012')65.0)[12.0, 19.0, 21.0, 12.0])You may also notice that first_bridge is different from the first bridge in the dataset file itself. This is because the data has been cleaned to suit our needs. For example:
[12.0, 19.0, 21.0, 12.0])MISSING_BCIThe data is not magically converted into this “clean” format – you will be implementing functions that transform the text data found in the files into a format that is more useful to our program.
The bridge_functions.py file includes many constants to use when indexing the nested data. you should be using these constants in the bodies of your functions. For example, what should we write if we wanted to access the year a bridge was built?
Consider the following code that does not use the constants:
>>> # Assume that first_bridge is a list containing data
>>> first_bridge[5]
'1965'How did I know to use index 5? Am I expected to memorize all the indexes? The answer is no; you should not write code like above. Instead, use the constants to provide context into which data feature you are accessing:
>>> # Assume that first_bridge is a list containing data
>>> first_bridge[COLUMN_YEAR_BUILT]
'1965'The following table shows how the dataset file and Python data are related through constants that begin with the prefix COLUMN_. The table also includes the data type that you should expect to find if you were to index a bridge list (like first_bridge) using that constant.
| Column Name | Constant to use as Index | Data Type |
|---|---|---|
| ID | COLUMN_ID |
int |
| STRUCTURE | COLUMN_NAME |
str |
| HWY NAME | COLUMN_HIGHWAY |
str |
| LATITUDE | COLUMN_LAT |
float |
| LONGITUDE | COLUMN_LON |
float |
| YEAR BUILT | COLUMN_YEAR_BUILT |
str |
| LAST MAJOR REHAB | COLUMN_LAST_MAJOR_REHAB |
str |
| LAST MINOR REHAB | COLUMN_LAST_MINOR_REHAB |
str |
| # OF SPANS | COLUMN_NUM_SPANS |
int |
| SPAN DETAILS | COLUMN_SPAN_DETAILS |
List[float] |
| DECK LENGTH | COLUMN_DECK_LENGTH |
float |
| LAST INSPECTION DATE | COLUMN_LAST_INSPECTED |
str |
| CURRENT BCI | N/A | N/A |
| Remaining Columns | COLUMN_BCI |
List[list] |
Note that the COLUMN_ID in our inner list is an integer, which is very different from the ID column in the dataset.
Our inner list does not contain the CURRENT BCI column from the dataset (instead, you will implement a function to find the most recent BCI score). Moreover, the remaining columns in the dataset that contain BCI scores are stored in another list (at index COLUMN_BCI) with type List[list]. This list contains exactly two lists:
INDEX_BCI_YEARS with type List[str] and includes the years in decreasing order.INDEX_BCI_SCORES with type List[float] and includes the BCI scores. Empty scores in the dataset have a value of MISSING_BCI.These two lists are parallel lists and should have the same length. Consider the following example:
>>> # Assume that first_bridge is a list containing data
>>> # Assume that MISSING_BCI refers to the value -1.0
>>> first_bridge[COLUMN_BCI][INDEX_BCI_YEARS]
['2013', '2012', '2011', '2010', '2009', '2008', '2007', '2006', '2005', '2004', '2003', '2002', '2001', '2000']
>>> first_bridge[COLUMN_BCI][INDEX_BCI_SCORES]
[-1.0, 72.3, -1.0, 69.5, -1.0, 70.0, -1.0, 70.3, -1.0, 70.5, -1.0, 70.7, 72.9, -1.0]
>>> len(first_bridge[COLUMN_BCI][INDEX_BCI_YEARS])
14
>>> len(first_bridge[COLUMN_BCI][INDEX_BCI_SCORES])
14From the example above, we can see that first_bridge has no BCI score in the year 2013 (see index 0 of both lists). But it does have a BCI score of 72.3 in the year 2012 (see index 1 of both lists). Therefore, first_bridge’s most recent BCI score is 72.3.
The bridges have their locations represented as a latitude and longitude, which we typically refer to as (lat, lon) for short. If you are curious, you can always search for a specific location online (e.g., with Google Maps):
It is very convenient to be able to calculate the straight-line distance between two locations. But this is actually a little tricky due to the curvature of the earth. We are providing you with the full implementation of a function, calculate_distance, that will accurately return the distance between two (lat, lon) points. You do not need to know how this function works – you only need to know how to use it.
At a high-level, your next steps are to:
bridge_functions.py.a2_checker.py, and pyta.bridge_functions.py.a2_checker.py.This assignment is divided into four parts. In parts 1 to 3, you will implement functions and run them using sample data that is already in bridge_functions.py. In part 4, you will implement functions that allow us to clean the data from the original dataset files so that we can use them in Python. Once you are done part 4, you will be able to run your functions from parts 1 to 3 with real data!
Please download the Assignment 2 Files and extract the zip archive. After you extract the zip file, you should see a similar directory structure to:
a2/
├─── pyta/
├─── many pyta files...
├─── a2_checker.py
├─── bridge_functions.py
├─── bridge_data_small.csv
├─── bridge_data_large.csvIn total, we have provided you with four files and a directory called pyta. We briefly discussed bridge_data_small.csv and bridge_data_large.csv above. The other two files are Python files:
bridge_functions.pyThis is the file where you will write your solution. Your job is to complete the file by implementing all the required functions. See below for more details.a2_checker.pyThis is a checker program that you should use to check your code. You will not modify this file. See below for more information about a2_checker.py.In this part, you will focus on working with the data by searching through it. You should not mutate any of the list inputs to these functions. You should refer to the section Indexing with Constants for help.
find_bridge_by_id(List[list], int) -> listNotes:
find_bridges_in_radius(List[list], float, float, int, List[int]) -> List[int]Notes:
calculate_distance function in the body. See the Calculating Distance section for help.get_bridge_condition(List[list], int) -> floatNotes:
calculate_average_condition(list, int, int) -> floatNotes:
In this part, you will focus on mutating the data. Notice how the wording of the docstring descriptions has changed (the descriptions do not begin with the word “Return”). Notice also that the return type for these functions is None, so nothing is returned.
inspect_bridge(List[list], int, str, float) -> NoneNotes:
rehabilitate_bridge(List[list], List[int], str, bool) -> NoneNotes:
In this part, you will implement an algorithm to help inspectors pick the sequence of bridges they should inspect. You will do this in two parts. First, by implementing a function that finds the bridge (from a subset of bridges) that is in the worst condition. Second, by implementing a function that targets the worst bridge within a certain radius, then moving on to the next bridge, until the desired number of bridges have been inspected.
find_worst_bci(List[list], List[int]) -> intNotes:
map_route(List[list], float, float, int, int) -> List[int]Notes:
while loopIn this part, we will finally start working with the real data files. The clean_data function is already implemented for you. However, it won’t work correctly until you implement the functions below. Once you are done Part 4, then you can start loading the dataset files we have provided you. After that, run your functions using real data instead of just the docstring examples.
clean_length_data(str) -> floatNotes:
trim_from_end(list, int) -> NoneNotes:
clean_span_data(str) -> List[float]Notes:
clean_bci_data(list) -> NoneNotes:
The last step in the Function Design Recipe is to run your function. You can use the a2_checker.py file to check for style and type contracts. You can use the doctest module to run the examples we have provided you in the docstrings. If you pass all of these tests, it does not mean that your function is 100% correct! You must do your own additional testing (e.g., by calling your functions with different arguments in the shell).
A2_CHECKER.PYWe are providing a checker module (a2_checker.py) that tests three things:
To run the checker, open a2_checker.py and run it. Note: the checker file should be in the same directory as bridge_functions.py and pyta, as provided in the starter code zip file. After running the checker, be sure to scroll up to the top of the shell and read all the messages!
In this assignment, we have provided you with several doctest examples and sample data.
A quick way to run all the doctest examples automatically is by importing the doctest module and calling one of its functions. We have already included the code to do this for you at the bottom of the starter file:
if __name__ == '__main__':
# Automatically run all doctest examples to see if any fail
import doctest
doctest.testmod()Delivering a high-quality product at a reasonable price is not enough anymore.
That’s why we have developed 5 beneficial guarantees that will make your experience with our service enjoyable, easy, and safe.
You have to be 100% sure of the quality of your product to give a money-back guarantee. This describes us perfectly. Make sure that this guarantee is totally transparent.
Read moreEach paper is composed from scratch, according to your instructions. It is then checked by our plagiarism-detection software. There is no gap where plagiarism could squeeze in.
Read moreThanks to our free revisions, there is no way for you to be unsatisfied. We will work on your paper until you are completely happy with the result.
Read moreYour email is safe, as we store it according to international data protection rules. Your bank details are secure, as we use only reliable payment systems.
Read moreBy sending us your money, you buy the service we provide. Check out our terms and conditions if you prefer business talks to be laid out in official language.
Read more